ローカルAI環境を語る上で避けては通れない「Ollama」。OllamaはPCのローカル環境でLlama 3やQwen2などの高性能AIモデル(LLM)を動作させるバックエンドツールです。単体で使う場合は、ブラウザ上でChatGPTのように使えるフロントエンドGUIの「Open WebUI」を使うことが多いです。ローカルで完結するため、情報漏洩リスクが少なく、無料で利用できます。
Docker環境で導入
導入は手軽で、Docker環境があればすぐです。下記を端末にコピペするだけです。
#!/bin/bash
# =============================================
# Open WebUI + Ollama セルフホスト自動インストールスクリプト (Ubuntu)
# 前提:Docker導入済み
# Ollamaデータ:/opt/docker/ollama
# =============================================
set -euo pipefail
echo "=== Open WebUI + Ollama インストール開始 ==="
# -----------------------------------------------
# 前提チェック
# -----------------------------------------------
if ! command -v docker &>/dev/null; then
echo "❌ Dockerが見つかりません。先にDockerをインストールしてください。"
exit 1
fi
if ! docker info &>/dev/null; then
echo "❌ Dockerデーモンに接続できません。"
echo " sudo systemctl start docker を実行するか、"
echo " 現在のユーザーをdockerグループに追加してください:"
echo " sudo usermod -aG docker \$USER && newgrp docker"
exit 1
fi
echo "✅ Docker確認OK: $(docker --version)"
# -----------------------------------------------
# ディレクトリ準備
# -----------------------------------------------
OLLAMA_DIR="/opt/docker/ollama"
WEBUI_DIR="/opt/docker/open-webui"
echo "データディレクトリを作成中..."
sudo mkdir -p "$OLLAMA_DIR"
sudo mkdir -p "$WEBUI_DIR"
# 実行ユーザーが書き込めるよう所有者を変更
sudo chown -R "$USER":"$USER" "$OLLAMA_DIR"
sudo chown -R "$USER":"$USER" "$WEBUI_DIR"
echo " Ollamaデータ : $OLLAMA_DIR"
echo " WebUIデータ : $WEBUI_DIR"
# -----------------------------------------------
# 既存コンテナの停止・削除(再実行時の冪等性)
# -----------------------------------------------
if docker ps -a --format '{{.Names}}' | grep -q '^open-webui$'; then
echo "既存の open-webui コンテナを停止・削除します..."
docker stop open-webui
docker rm open-webui
fi
# -----------------------------------------------
# イメージ取得
# -----------------------------------------------
echo "Open WebUI + Ollamaイメージをダウンロード中..."
docker pull ghcr.io/open-webui/open-webui:ollama
# -----------------------------------------------
# コンテナ起動(CPU版)
# -----------------------------------------------
echo "コンテナを起動中..."
docker run -d \
--name open-webui \
--restart always \
-p 3000:8080 \
-v "$OLLAMA_DIR":/root/.ollama \
-v "$WEBUI_DIR":/app/backend/data \
ghcr.io/open-webui/open-webui:ollama
# -----------------------------------------------
# 起動確認
# -----------------------------------------------
echo "起動確認中(最大60秒待機)..."
for i in $(seq 1 12); do
if curl -sf http://localhost:3000 &>/dev/null; then
echo "✅ WebUIが応答しました"
break
fi
echo " 待機中... (${i}/12)"
sleep 5
done
echo ""
echo "=========================================="
echo "✅ インストール完了!"
echo "ブラウザで http://localhost:3000 にアクセスしてください"
echo "(サーバーIP:3000 でもOK)"
echo ""
echo "初回はアカウント作成(最初のユーザーが管理者)"
echo "左側の「Models」から好きなモデルを検索・ダウンロード:"
echo "おすすめ:llama3.2、gemma2:9b、mistral、phi3 など"
echo ""
echo "データ保存先:"
echo " Ollamaモデル : $OLLAMA_DIR"
echo " WebUI設定 : $WEBUI_DIR"
echo "=========================================="
echo ""
echo "▶ コンテナ管理コマンド:"
echo " 停止 : docker stop open-webui"
echo " 起動 : docker start open-webui"
echo " ログ : docker logs -f open-webui"
echo " 削除 : docker stop open-webui && docker rm open-webui"
echo ""
echo "=========================================="
echo "GPU(NVIDIA)を使いたい場合:"
echo "1. NVIDIAドライバ+NVIDIA Container Toolkitを別途インストール"
echo " https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/"
echo "2. 下記コマンドで再起動:"
echo " docker stop open-webui && docker rm open-webui"
echo " docker run -d --name open-webui --restart always \\"
echo " --gpus=all \\"
echo " -p 3000:8080 \\"
echo " -v $OLLAMA_DIR:/root/.ollama \\"
echo " -v $WEBUI_DIR:/app/backend/data \\"
echo " ghcr.io/open-webui/open-webui:ollama"
echo "=========================================="Webブラウザから使用
インストールが完了したら、Webブラウザで http://localhost:3000 にアクセスすれば利用できます。
(サーバーIP:3000 でもOK)
初回はアカウントを作成します。(最初のユーザーが管理者)。

アカウントを作成したら、まずは左側の「モデルを選択」から好きなモデルを検索して、プルでダウンロードします。おすすめのモデルは、llama3.2、gemma2:9b、mistral、phi3 など
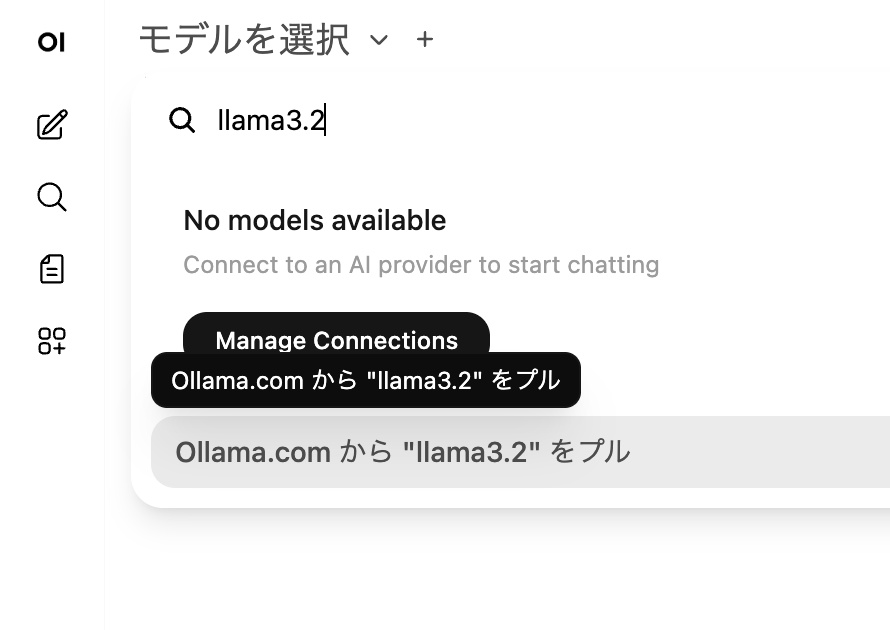
モデルのダウロードが完了したら、上部のドロップダウンでモデルを即切り替えれば、会話を開始できます。

おもなモデル一覧
選び方の目安をまとめると、
CPU環境(GPUなし)のおすすめ
llama3.2:3b、phi3、gemma2:2bあたりが動かしやすい。RAM 8GB以上あれば快適。
GPU(VRAM 8〜12GB)のおすすめ
- 汎用なら
mistral・gemma3:12b・qwen2.5:14b - コードなら
qwen2.5-coder:7b・deepseek-coder:6.7b - 推論・思考なら
deepseek-r1:7b・qwen3:8b
RAG・セマンティック検索を組み合わせる場合
- チャットモデルと並行して
nomic-embed-text(超軽量)かbge-m3(多言語)を入れておくと便利。